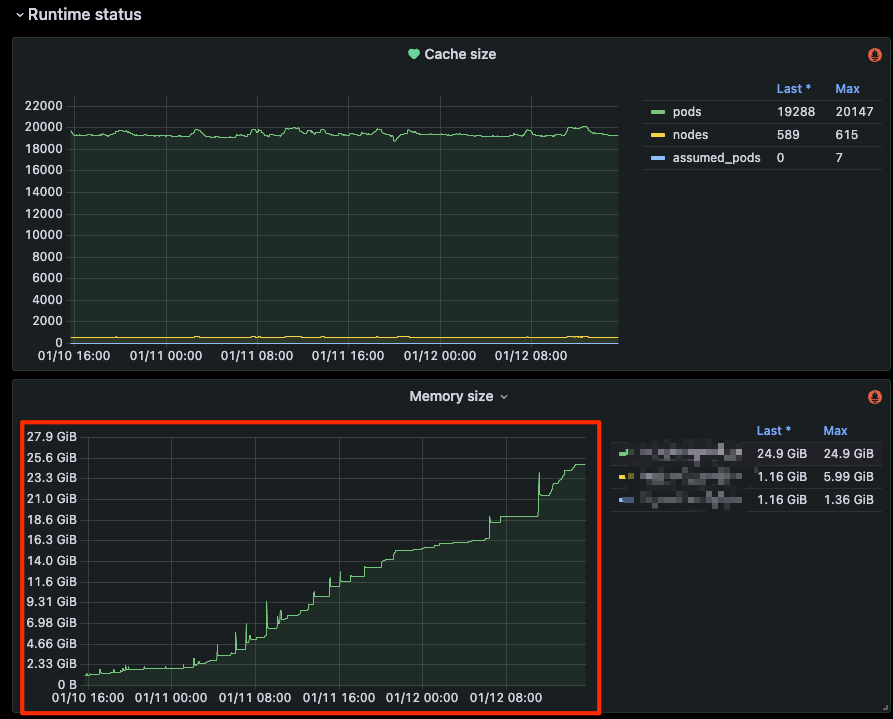
Before the new year, a colleague upgraded the Kubernetes scheduler to version 1.28.3 and observed abnormal memory behavior. Let’s take a look together. In the context of fluctuating business tidal changes affecting both pods and nodes in the cluster, memory usage shows a continuous upward trend until reaching Out Of Memory (OOM) conditions.
Issue
The following data is all publicly available information from the community.
The triggering scenarios include the following two types (there are also other reproduction methods in the community):
- case 1
1 | for (( ; ; )) |
- case 2
1 | 1. Create a Pod with NodeAffinity under the situation where no Node can accommodate the Pod. |
Our findings in the community revealed multiple instances of similar memory anomaly scenarios, with various methods of reproduction. The conclusion regarding the above issue is as follows:
The Kubernetes community defaulted to enabling the scheduling feature SchedulerQueueingHints in version 1.28, which led to memory anomalies in the scheduler component. To temporarily address memory-related issues, the community adjusted this feature to default to disabled in version 1.28.5. However, as the problem has not been completely resolved, it is advisable to exercise caution when enabling this feature.
Technical Background
This section introduces the following content:
- Introduction to Kubernetes scheduler related data structures
- Introduction to Kubernetes scheduler QueueingHint
- Doubly linked lists in Golang
K8s-Scheduler Introduction
The PriorityQueue is an interface implementation of the SchedulingQueue. It holds the highest priority pod ready for scheduling at its head. PriorityQueue contains the following important fields:
- activeQ: This queue holds pods ready for scheduling. Newly added pods are placed into this queue. When the scheduling queue needs to perform scheduling, it fetches pods from this queue. activeQ is implemented using a heap.
- backoffQ: This queue holds pods that have been determined to be unschedulable for various reasons (such as not meeting node requirements). These pods will be moved to activeQ to attempt scheduling again after a certain backoff period. backoffQ is also implemented using a heap.
- unschedulablePods: This map data structure holds pods that cannot be scheduled for various reasons. Instead of directly placing them in backoffQ, they are recorded here. When conditions are met, they will be moved to activeQ or backoffQ. The scheduling queue periodically cleans up pods in unschedulablePods.
- inFlightEvents: This is used to store events received by the scheduling queue (with the entry value as clusterEvent) and pods that are currently being processed (with the entry value as *v1.Pod). It’s based on a doubly linked list implemented in Go.
- inFlightPods: This holds the UIDs of all pods that have been popped but have not yet had Done called on them. In other words, it keeps track of all pods that are currently being processed (i.e., in scheduling, in admit, or in binding phases).
1 | // PriorityQueue implements a scheduling queue. |
For a comprehensive introduction to Kubernetes, please refer to An In-depth Introduction to Kubernetes Scheduling: Framework. Updates on the latest Kubernetes scheduler will be provided subsequently.
QueueingHint
Kubernetes scheduler introduced the QueueingHint feature to provide recommendations for re-queueing pods from each plugin. This aims to reduce unnecessary scheduling retries, thereby enhancing scheduling throughput. Additionally, it skips backoff under appropriate circumstances to further improve pod scheduling efficiency.
Background
Currently, each plugin can define when to retry scheduling pods that have been rejected by the plugin through the EventsToRegister mechanism.
For example, the NodeAffinity plugin may retry scheduling pods when nodes are added or updated because newly added or updated nodes may have labels that match the node affinity on the pod. However, in practice, a large number of node update events occur in the cluster, which does not guarantee successful scheduling of pods previously rejected by NodeAffinity.
To address this issue, the scheduler introduced more refined callback functions to filter out irrelevant events, thereby only retrying pods that are likely to be successfully scheduled in the next scheduling cycle.
Furthermore, the Dynamic Resource Allocation (DRA) scheduling plugin sometimes needs to reject pods to wait for status updates from device drivers. Therefore, certain pods may require several scheduling cycles to be scheduled. For this scenario, the wait time for fallback is longer compared to waiting for device driver status updates. Hence, there is a need to allow plugins to skip fallback in specific cases to improve scheduling performance.
Implementation Goals
To improve scheduling throughput, the community proposed the following enhancements:
- Introduction of QueueingHint
- Introducing
QueueingHintinto theEventsToRegistermechanism, allowing plugins to provide recommendations for re-queuing pods.
- Introducing
- Enhancement of Pod Tracking and Re-queueing Mechanism
- Optimizing the implementation for tracking pods currently being processed in the scheduling queue.
- Implementing a mechanism to re-queue rejected pods to appropriate queues.
- Optimizing the backoff strategy for rejected pods, allowing plugins to skip backoff in specific cases to improve scheduling throughput.
Potential Risks
1. Errors in Implementation Leading to Pods Being Unschedulable in unschedulablePods for Extended Periods
If a plugin is configured with QueueingHint but misses some events that could make pods schedulable, pods rejected by that plugin may remain stuck in unschedulablePods for a long time.
Although the scheduling queue periodically cleans up pods in unschedulablePods (default is 5 minutes, configurable).
2. Increase in Memory Usage
As the scheduling queue needs to retain events occurring during scheduling, the memory usage of kube-scheduler will increase. Therefore, the busier the cluster, the more memory it may require.
Although it’s not possible to completely eliminate memory growth, releasing cached events as soon as possible can slow down the rate of memory growth.
3. Significant Changes in
EventsToRegisterinEnqueueExtension
Developers of custom scheduler plugins need to perform compatibility upgrades, as the return type of EventsToRegister in EnqueueExtension has changed from ClusterEvent to ClusterEventWithHint. ClusterEventWithHint allows each plugin to filter out more useless events through a callback function called QueueingHintFn.
To simplify the migration work, an empty QueueingHintFn is considered to always return Queue. Thus, if they only want to maintain the existing behavior, they only need to change ClusterEvent to ClusterEventWithHint without registering any QueueingHintFn.
Design of QueueingHints
The return type of the EventsToRegister method has been changed to []ClusterEventWithHint.
1 | type EnqueueExtensions interface { |
Each ClusterEventWithHint structure consists of a ClusterEvent and a QueueingHintFn. When an event occurs, the QueueingHintFn is executed to determine whether the event can make the pod eligible for scheduling.
1 | type ClusterEventWithHint struct { |
The type QueueingHintFn is a function with a return type of (QueueingHint, error). Here, QueueingHint is an enumeration type with possible values of QueueSkip and Queue. The invocation of QueueingHintFn occurs before moving pods from unschedulableQ to backoffQ or activeQ. If an error is returned, the QueueingHint provided by the caller will be treated as QueueAfterBackoff, which ensures that the pod does not remain indefinitely in the unschedulableQ queue, regardless of the returned result.
When to Skip/Not Skip Backoff
The backoffQ prevents pods that are “long-term unschedulable” from blocking the queue, maintaining a lightweight queue with high throughput.
The longer a pod is rejected during the scheduling cycle, the longer it waits in the backoffQ.
For example, when NodeAffinity rejects a pod, and later returns Queue in its QueueingHintFn, the pod needs to wait for backoff before retrying scheduling.
However, certain plugins are designed to experience some failures during the scheduling cycle itself. For instance, the built-in DRA (Dynamic Resource Allocation) plugin, at the Reserve extension, informs the resource driver of the scheduling result and rejects the pod once to wait for a response from the resource driver. For such rejection scenarios, it should not be considered wasted scheduling cycles. Although a specific scheduling cycle fails, the scheduling result based on that cycle can facilitate pod scheduling. Therefore, pods rejected for this reason do not need to be penalized (backoff).
To support this scenario, we introduce a new state, Pending. When the DRA plugin rejects a pod using Pending and later returns Queue in its QueueingHintFn, the pod skips backoff and is rescheduled.
How QueueingHint Works
When Kubernetes cluster events occur, the scheduling queue executes the QueueingHintFn of those plugins that rejected pods in the previous scheduling cycle.
The following scenarios describe how they are executed and how pods are moved:
Pod Rejected by One or More Plugins
Suppose there are three nodes. When a pod enters the scheduling cycle, one node rejects the pod due to insufficient resources, and the other two nodes reject it due to mismatching node affinity.
In this scenario, the pod is rejected by the NodeResourceFit and NodeAffinity plugins and is eventually placed in unschedulableQ.
Subsequently, whenever cluster events registered in these plugins occur, the scheduling queue notifies them via QueueingHint. If any QueueingHintFn from NodeResourceFit or NodeAffinity returns Queue, the pod is moved to activeQ or backoffQ. (For example, when a NodeAdded event occurs, QueueingHint from NodeResourceFit returns Queue because the pod may be schedulable to the new node.)
Whether it moves to activeQ or backoffQ depends on how long the pod has been in unschedulableQ. If the time spent in unschedulableQ exceeds the expected pod backoff delay time, it is moved directly to activeQ. Otherwise, it is moved to backoffQ.
Pod Rejected due to Pending State
When the DRA plugin returns Pending for a pod during the Reserve extension phase, the scheduling queue adds the DRA plugin to the pod’s pendingPlugins dictionary and returns the pod.
When a call to the QueueingHint of the DRA plugin returns Queue in subsequent invocations, the scheduling queue places the pod directly into activeQ.
1 | // Reserve reserves claims for the pod. |
Tracking Pods Being Processed in the Scheduling Queue
By introducing QueueingHint, we can only retry scheduling when specific events occur. But what if these events happen during pod scheduling?
The scheduler takes a snapshot of the cluster data and schedules pods based on the snapshot. The snapshot is updated each time a scheduling cycle is initiated, meaning the same snapshot is used within the same scheduling cycle.
Consider a scenario where, during the scheduling of a pod, it is rejected due to no nodes meeting the pod’s node affinity, but a new node matching the pod’s node affinity is added during the scheduling process.
As mentioned earlier, this new node is not considered a candidate node within the current scheduling cycle. Therefore, the pod is still rejected by the node affinity plugin. The issue arises if the scheduling queue puts the pod into unschedulableQ, as the pod would still need to wait for another event even though a node matching the pod’s node affinity requirement is available.
To prevent scenarios where pods miss events during scheduling, the scheduling queue records events occurring during pod scheduling and determines the pod’s queueing position based on these events and QueueingHint.
Therefore, the scheduling queue caches events from the time a pod leaves the scheduling queue until it returns to the scheduling queue or is scheduled. When the cached events are no longer needed, they are discarded.
Golang Doubly Linked List
*list.List is a data structure in Go’s standard library container/list package, representing a doubly linked list. In Go, doubly linked lists are a common data structure used to provide efficient performance for operations like element insertion, deletion, and traversal.
Here’s a brief overview of the *list.List structure:
- Definition:
*list.Listis a pointer to a doubly linked list. It contains pointers to the head and tail of the list, as well as information about the length of the list. - Features: Each node in the doubly linked list contains pointers to the previous and next nodes, making operations like inserting and deleting elements in the list efficient.
- Usage:
*list.Listis commonly used in scenarios where frequent insertion and deletion operations are required, especially when the number of elements is not fixed or the order may change frequently.
Here’s a demonstration of how to use *list.List in Go:
1 | goCopy codepackage main |
The PushBack method adds a new element to the end of the list and returns a pointer to the new element (*list.Element). This pointer can be used for further operations on the element, such as removal or modification.
The *list.Element structure contains pointers to the previous and next elements in the list, as well as a field for storing the element’s value. By returning a *list.Element pointer, we can conveniently access the newly added element when needed for further operations. To remove an element from the doubly linked list, you can use the list.Remove() method. This method takes a list element as input and removes the element from the list.
1 | package main |
outputs:
1 | 1 |
In this example, we remove the second element (with a value of 2) from the linked list.
A brief analysis
Let’s dive straight into analyzing the memory usage using pprof. Here’s a partial list of pprof profiles:

Here, we can observe that memory usage is primarily concentrated in protobuf’s Decode. Without delving into specific pprof analysis, we can consider three potential factors:
- Whether grpc-go has memory issues
- Whether there are issues with Go itself
- Whether Kubernetes has memory issues
Regarding the first assumption, we can check related issues in grpc-go. However, recent reports do not indicate any memory anomalies. As for issues with Go itself, it doesn’t seem likely, although we did find a related Transparent Huge Pages (THP) issue, which we can briefly discuss later. Thus, the most probable cause would be an issue within Kubernetes itself. However, considering that (*FieldsV1).Unmarshal hasn’t been modified for 5 years, it’s highly unlikely to be the source of the problem. Therefore, let’s delve deeper into analyzing pprof.
1 | k8s.io/apimachinery/pkg/apis/meta/v1.(*FieldsV1).Unmarshal |
过段时间:
1 | k8s.io/apimachinery/pkg/apis/meta/v1.(*FieldsV1).Unmarshal |
In the continuously growing list of pods, I noticed some unreleased data that seemed to align with the results of my previous analysis using pprof. Interestingly, pods are the only continuously changing objects. Therefore, I attempted another troubleshooting method to verify if the community had resolved this issue. I used minikube to launch Kubernetes version 1.18.5 locally for investigation. Fortunately, I couldn’t reproduce the issue, indicating that the problem might have been fixed after version 1.18.5.
To narrow down the investigation further, I asked my colleagues to inspect the commit history between these three minor versions. Eventually, we found a PR that closed the SchedulerQueueingHints feature. As mentioned in the technical background, the SchedulerQueueingHints feature could potentially lead to memory growth issues.
By examining the PriorityQueue structure, it was evident that the logic handling the feature was controlled by isSchedulingQueueHintEnabled. If the QueueingHint feature is enabled, when executing the Pop method to schedule pods, the UID of the corresponding pod in inFlightPods needs to be populated with the same linked list as inFlightEvents.
1 | func (p *PriorityQueue) Pop(logger klog.Logger) (*framework.QueuedPodInfo, error) { |
So, when are the linked list fields removed? We can observe that the only time they are removed is when the pod completes its scheduling cycle, that is, when the Done method is called.
1 | func (p *PriorityQueue) Done(pod types.UID) { |
Here, it can be observed that the later the timing of Done, the more pronounced the memory growth, and if pod events are ignored or missed, abnormal memory growth in the linked list can also occur. Some fixes for the above scenario can be seen:
- A PR, such as #120586, which emphasizes calling
Done()as soon as possible. - The
QueueingHintof the NodeAffinity/NodeUnschedulable plugins missed relevant Node events, as seen in PR#122284.
Despite these modifications, such issues are far from over.
Reference
- https://github.com/kubernetes/kubernetes/issues/122725
- https://github.com/kubernetes/kubernetes/issues/122284
- https://github.com/kubernetes/kubernetes/pull/122289
- https://github.com/kubernetes/kubernetes/issues/118893
- https://github.com/kubernetes/enhancements/blob/cf6ee34e37f00d838872d368ec66d7a0b40ee4e6/keps/sig-scheduling/4247-queueinghint/README.md?plain=1#L579
- https://github.com/kubernetes/kubernetes/issues/122661
- https://github.com/kubernetes/kubernetes/pull/120586
- https://openai.com/
- https://github.com/kubernetes/kubernetes/issues/118059